
Niezależnie od tego, czy studiujesz statystykę czy potrzebujesz dodatkowej pomocy w zajęciach, te problemy praktyczne ci pomogą. Chociaż statystyczne metody analizy i modelowania statystycznego są często powiązane bezpośrednio z analizą danych, ważne jest, aby zrozumieć arytmetykę leżącą u podstaw tych metod analitycznych.
Podczas gdy większość pakietów oprogramowania, takich jak SPSS i Stata, wymaga niewielkich obliczeń statystyka lub nie wymaga ich wcale, ważne jest, aby wiedzieć, jak działa to oprogramowanie. U podstaw większości analiz statystycznych leży gałąź matematyki zwana statystyką Bayesowską. Jest mało prawdopodobne, że będziesz musiał poradzić sobie z twierdzeniem Baye'a po pierwszym kursie statystyki wprowadzającej, ale ważne jest, aby zawsze pamiętać o jego konsekwencjach dla tak zwanego wnioskowania Bayesowskiego.

Twierdzenie Baye'a używa prawdopodobieństwa do opisania prawdopodobieństwa zdarzenia, biorąc pod uwagę wcześniejsze informacje o tym samym zdarzeniu, zwane także wcześniejszym. Na przykład, jeśli chcesz obliczyć prawdopodobieństwo, że ciężarówka z lodami w twojej okolicy przyjedzie w dzień, biorąc pod uwagę, że jest to słoneczny dzień, możesz skorzystać z wcześniejszych danych empirycznych, aby oszacować to prawdopodobieństwo.
Definicja wnioskowania Byesowskiego polega zatem na wydedukowaniu prawdopodobieństwa zdarzenia z rozkładu populacji przy użyciu twierdzenia Baye'a. To jest podstawa wielu problemów statystycznych i testów, dlatego ważne jest, aby to pamiętać, ponieważ wiele razy nie zobaczysz tego dokładnie. W tym przewodniku zostaną przedstawione trzy sekcje przykładów, które odbiegają od tej teorii, przy czym każda sekcja opiera się na tej teorii.










Podstawowe obliczenia statystyczne
Aby rozwiązać problemy praktyczne w tym rozdziale, ważne jest zrozumienie podstawowej statystyki. Najprawdopodobniej zapoznałeś się z prawdopodobieństwem i rozumiesz znaczenie prawdopodobieństwa warunkowego w budowaniu nawet najprostszej analizy danych eksploracyjnych. Statystyki i prawdopodobieństwo idą w parze, dlatego ważne jest, aby zrozumieć przed przystąpieniem do rozwiązywania tych problemów.
Definicje i umiejętności, które należy zrozumieć, aby rozwiązać problemy w tej sekcji, obejmują:
- Teoria limitów centralnych
- Tendencja centralna
- Standardowy rozkład normalny
- Próbka Średnia, Mediana i Tryb
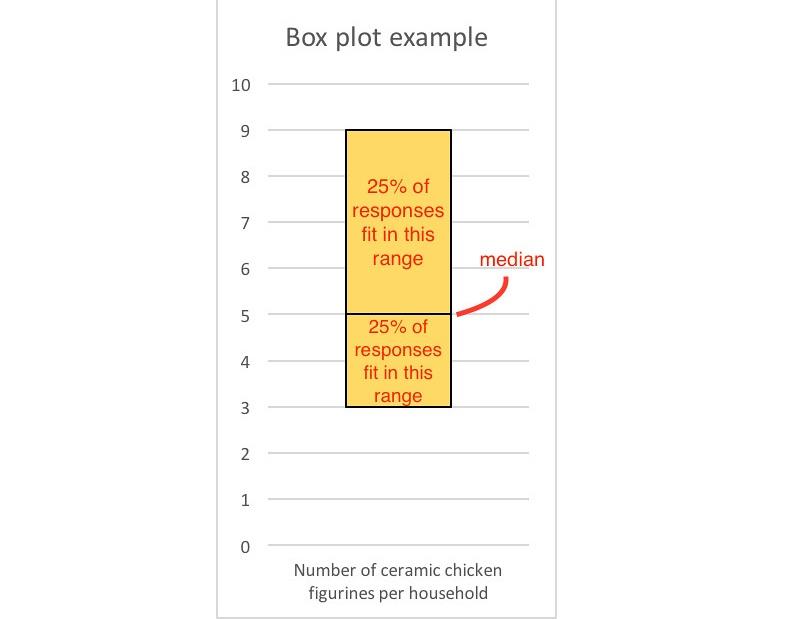
Pytanie 1: Zbuduj wykres pudełkowy na podstawie następującego wykresu Steam-and-leaf
Zarówno wykres pudełkowy, jak i diagramy steam-and-leaf są różnymi sposobami wyświetlania rozkładu określonej zmiennej w danych. Różnica polega na tym, że wykres pudełkowy pokazuje sposób dystrybucji danych w oparciu o rozkład normalny. Aby móc zbudować wykres pudełkowy, ważne jest, aby zrozumieć, co reprezentuje każdy punkt na wykresie.
Mediana jest środkowa, gdzie 1, 2, 3 i 4 reprezentują cztery różne kwartyle twoich danych. Oznacza to, że jeśli weźmiemy pierwszy kwartyl, oznacza to, że 25% twoich danych znajduje się w tym regionie. W kwartylu 3 oznacza to, że 75% twoich danych znajduje się w tym punkcie i poniżej. Kwartyl 0 reprezentuje minimum, a kwartyl 4 reprezentuje maksimum. Jest to następnie porównywane z rozkładem normalnym:

Patrząc na powyższe zdjęcie, widzimy, że około 50% naszych danych przypada między I i III kwartałem. Poniżej pierwszego lub powyżej trzeciego kwartału tylko około 25% naszych danych leży. Poza minimum i maksimum, te punkty danych są uważane za wartości odstające. Wartość odstająca to punkt danych, który nie jest normalny w stosunku do populacji próby.

Nasza fabuła, która wygląda jak:
Pytanie 2: Jak obliczyć i zinterpretować współczynnik korelacji
Nawiązując się na ostatniej sekcji, ważne jest, aby zrozumieć, w jaki sposób poszczególne zmienne w zestawie danych odnoszą się do siebie. Jest to szczególnie przydatne, ponieważ niezależnie od typów danych, które napotkasz, będziesz w stanie zastosować te narzędzia bez względu na to, jakiego rodzaju pojęć statystycznych używasz. Jedną ważną tabelą, którą napotkasz, jest tabela korelacji i kowariancji między zmiennymi w zbiorze danych.
Podczas gdy definicja korelacji jest siłą związku między dwiema zmiennymi, kowariancja odnosi się do tego, jak te dwie zmienne się różnią. Celem tych liczb jest możliwość zmierzenia, jak blisko każda zmienna odnosi się do siebie.
Na przykład, jeśli masz zestaw danych dotyczących zdrowych dzieci w gimnazjum, wzrost i waga najprawdopodobniej będą miały wysoką korelację. Z drugiej strony zmienne takie jak wysokość i ulubiony kolor prawdopodobnie nie będą miały wysokiej korelacji. W modelach regresji obliczenie i interpretacja współczynnika korelacji jest niezwykle ważna.
Najpopularniejsza tabela wygląda tak i nazywa się tabelą korelacji Pearsona:
Tabele korelacji mogą być proste, jeśli opanujesz ich interpretację i analizę.
Liczby w tabeli reprezentują współczynnik korelacji, który jest miarą tego, jak silny jest związek między zmiennymi w tabeli. Aby obliczyć współczynnik korelacji, jedyne potrzebne czynniki to odchylenie standardowe próbki i kowariancja próbki.
Odchylenie standardowe jest miarą tego, jak daleko twoje dane są rozłożone wokół średniej, nie należy mylić go ze standardowym błędem, czyli jak daleko twoje dane są rozłożone wokół średniej opartej nie na danych z próbki, ale poza faktycznej populacji.
Z drugiej strony, kowariancja jest miarą tego, jak dwie zmienne różnią się razem, co jest bardzo zależne od twoich danych próbki. Kowariancji nie należy mylić z wariancją, która mierzy tylko, jak jedna zmienna zmienia się w zbiorze danych.
Interpretacja współczynnika korelacji przebiega według trzech podstawowych zasad. Po pierwsze, liczby wzdłuż przekątnej powinny zawsze być równe jeden. Przekątna reprezentuje korelację między zmienną a samym sobą, która zawsze powinna wynosić 1 lub 100%. Na przykład, gdy korelacja między zmiennym ulubionym kolorem a tą samą zmienną wynosi 100%.
Druga zasada mówi, że wyższą powyżej 50% korelację należy uznać za wysoką korelację, podczas gdy poniżej 50% należy uznać za korelację słabą. W tym przykładzie, podczas gdy ulubiony kolor ma tylko 4% korelacji z wagą, waga i wzrost mają silną korelację wynoszącą prawie 90%.
Trzecia zasada polega na tym, że chociaż korelacje poniżej 50% są zwykle uważane za słabe, nie oznacza to, że nie mogą cię zainteresować. W tym przykładzie ulubiony kolor ma 57% korelacji z płcią. Chociaż nie jest to zbyt silna korelacja w stosunku do tabeli, wskazuje to na różnice płci, które mogą być warte dalszych badań.
Znajdź statystyka korepetycje na Superprof.
Pytanie 3: Jak interpretować testy statystyczne
Statystyki, jak być może zauważyłeś, w dużej mierze opierają się na informacjach, których się nauczyłeś. Dlatego ważne jest opanowanie podstaw statystyki, zanim zaczniesz rozumieć i ćwiczyć testy statystyczne.
Interpretacja testów statystycznych będzie się różnić w zależności od tego, który test wykonujesz. Dwa najczęstsze testy, których nauczysz się na początku swojej kariery statystycznej, to:
- Test Chi Square
- Test T
Oba testy obejmują testowanie hipotez, które wykorzystuje statystyki do testowania, czy zmienne w danych są powiązane, czy nie. Test T porównuje średnie z dwóch zmiennych i daje wgląd w to, jak te dwie zmienne są powiązane. Na przykład, porównując nowy lek z placebo, wyniki zdrowotne dwóch grup pacjentów można analizować za pomocą testu t.
Z drugiej strony można zastosować test Chi Square, aby ustalić, czy rozkład przykładowych danych pasuje do populacji, czy też dwie zmienne w tabeli kontyngencji są ze sobą powiązane.
Pierwszy test nazywa się testem dobroci dopasowania chi-Square, a drugi testem niezależności chi-Square. Przykład testu niezależności chi-kwadrat można znaleźć, próbując sprawdzić, czy poziom wykształcenia ma związek ze stanem cywilnym, porównując je z tabelą awaryjną.
Jeśli nie masz pewności, jaki test wykonać dla swojego zestawu danych, wpisz np. „korepetycje statystyka Warszawa” w wyszukiwarkę Superprof i znajdź pomoc specjalisty!
Poproś o dodatkową pomoc statystyczną
Na szczęście istnieje wiele zasobów, które mogą dostarczyć pomocnych wskazówek i samouczków, jeśli zmagasz się ze statystykami. Obejmują one szeroki zakres platform internetowych, takich jak Superprof i Khan Academy, a także podręczniki i inne materiały do czytania. Jednym ze świetnych źródeł uzyskania dodatkowej pomocy online w statystykach jest Wolfram Math and Statistics How To. Obie platformy internetowe nie tylko przedstawiają matematyczne elementy pojęć statystycznych, ale także szczegółowo je wyjaśniają.
Jeśli potrzebujesz dodatkowych wyjaśnień, przejście na Youtube może uratować życie. Jeśli szukasz pomocnych samouczków wideo, często najlepiej jest wyszukać słowa kluczowe terminów statystycznych, z którymi się zmagasz, i przeglądać, aby zobaczyć, który film ma najlepszy materiał. Jeśli wolisz, aby ktoś ci to wyjaśnił osobiście, korepetycje osobiste są świetną opcją. Najlepszym sposobem na skorzystanie z tego jest nie banie się poprosić swojego profesora o dodatkową pomoc. Każdy uczy się w innym tempie i na różne sposoby, dlatego ważne jest, aby o tym pamiętać, kontynuując swoją podróż statystyczną.
Podsumuj za pomocą AI
Oceń czy nasz artykuł był pomocny 😊 Oceń nas!



